- Published on
virtual memory 2
- Authors

- Name
- valery
- 0. 문제 제기 - 페이지 테이블이 왜 문제냐?
- 1. Linked list page table
- 2. Hashed page table
- 3. Inverted page table
- 4. Two-level Page Table
- 5. Multi-level page table
- 6. 페이지 테이블을 페이징 하자
- 7. TLB
- 8. 지금까지 배운 TLB / 페이지 테이블 / 디스크를 메모리 한 번 읽을 때 실제로 어떻게 맞물려 돌아가는지
0. 문제 제기 - 페이지 테이블이 왜 문제냐?
페이지 테이블을 통째로 만들면 너무 크다
근데 실제로 사용하는 공간은 매우 작다
- 실제 쓰는 부분만 매핑하자
- 방법1: 페이지 테이블 구조를 동적으로 확장 가능하게 만든다 (linked list, tree 같은 걸로)
- 방법2. indirection(중간단계)을 한 단계 더 둔다 — two-level, hashed, inverted 등등
1. Linked list page table
- 링리 연산하는것 자체가 오버헤드(메모리는 아낄 수 있지만)
- 그래서 트리로 함
2. Hashed page table
linked list = 공간 좋고 시간 안좋고 → hashed = 해시로 시간 살림 → clustered = 블록으로 공간 더 살림
bucket이 linked list를 들고있는 이유: 같은 bucket안에 다른 p들도 있을텐데 링크드 리스트로 검색하려고
각 element(버켓에 달린 노드)가 들고 있는 것:
- VPN (진짜 내가 찾는 p가 맞는지 비교용)
- 매핑된 프레임 번호
- next 포인터
흐름
- bucket: 해시 테이블에서 같은 해시값을 가진 항목들을 모아두는 저장 공간
- p: 페이지 번호
- d: offset
- r: frame 번호
p -> hash func(p%100 같은걸로) -> hash table -> bucket -> 링크드 리스트로 p와 같은 entry 검색 -> 일치하는 p값 찾으면 r값 매핑
d -> d
물리주소 r|d
변종: Clustered page table
한 entry가 페이지 하나가 아니라 연속된 페이지 블록을 통째로 매핑
가상주소를 아래와 같이 쪼갠다
[ Virtual Page Block Number | Block offset | Offset ]
해시 테이블 엔트리 하나는
VPBN | next | PPN0 | PPN1 | PPN2 | PPN3 이렇게 생김
즉 한 블록(연속된 페이지 4개)의 프레임 번호를 한 entry에 몰아 담는다.
페이지를 띄엄띄엄 쓰는 게 아니라 한 군데 모아서 연달아 쓰는 패턴일 때 entry 수가 4배로 줄어드니까 테이블이 더 작아진다
3. Inverted page table
1. 일반 페이지 테이블 vs Inverted page table
일반 페이지 테이블
일반 페이지 테이블은 프로세스마다 페이지 테이블이 있음
가상 페이지 번호 p로 바로 찾음
빠르지만 프로세스가 많고 가상주소공간이 크면 페이지 테이블 크기가 커짐
Inverted page table
칸(entry)을 가상 페이지 기준이 아니라 물리 프레임의 수만큼 만든다.
시스템 전체에 딱 하나의 테이블. 프로세스가 몇 개든 간에 상관없이
각 entry는 "이 물리 프레임에는 지금 어느 프로세스(PID)의 어느 가상 페이지(p)가 들어있다"를 저장한다
frame의 번호를 따로 저장해서 매핑시키지 않고 frame번호(i)자체가 엔트리의 인덱스
2. 흐름
CPU가 pid | p | d를 던지면:
- 테이블을 위에서부터 search 하면서 (PID, p)가 일치하는 entry를 찾음
- 일치한 entry가 몇 번째 칸이냐 = 그게 곧 물리 프레임 번호 i
- 물리주소 = i | d
3. 장점
- 테이블이 물리 메모리 크기에만 비례 - 메모리 절약 좋음
4. 단점
- 검색이 느리다(일반 테이블은 p로 한번에 찾을 수 있는데 얘는 pid, p를 들고 찾아야해서)
- PID관리가 필요
- 프로세스 종료 시 회수할 때 오버헤드가 엄청 크다(일반 테이블은 flush해버리면 되는데 얘는 pid들고 일일히 회수해줘야 함)
5. 보완책
검색이 너무 느리니까 hash table을 앞에 붙여서 검색 범위를 한 개 또는 많아야 몇 개 entry로 좁힌다.
그래서 실제 inverted page table은 거의 항상 해시랑 세트로 쓰인다.
4. Two-level Page Table
4MB짜리 테이블을 두조각(secondary table)으로 나눈다.
안쓰는 조각은 아예 만들지 않는다
virtual address를 3조각으로 아래처럼 쪼갠다
10bit 10bit 12bit
[ Master page # | Secondary page # | Offset ]
Master page #: 1차 페이지 테이블 조회해서 2차 테이블 연결점 찾음
Secondary page #: 2차 페이지 테이블 조회해서 frame number 조회
이후 offset과 frame number 조합해서 정확한 물리 주소 찾아냄
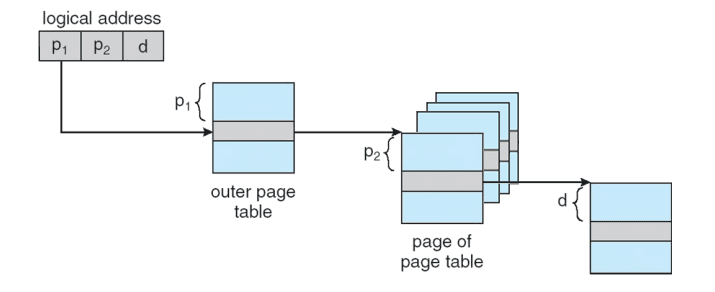
- p1 = Master page #
- p2 = Secondary page #
- d = Offset
추가
master page 10bit, secondary page 10bit로 쪼개면
2^10(1차 페이지 테이블 앤트리 개수) * 2^10(2차 페이지 테이블 엔트리 개수)개를 가져야 해서 메모리 양은 줄어들지 않는다
secondary page table의 개수: master page table의 엔트리 개수(2^10)
그래서 2^8, 2^12로 쪼개개 된다면,
secondary page table의 개수는 2^8개로 줄어들게 되지만 secondary page table의 entry는 2^12로 늘어나게 된다
최악의 경우
최악의 경우(모든 secondary page table를 모두 사용할 떄)는
master page table entry = 2^10, secondary page table entry = 2^10일 때,
secondary 전체 : 2^10개 테이블 × 1024 entry × 4byte
= 1024 × 4KB = 4MB
master 테이블 : 1024 entry × 4byte = 4KB ← 추가분
─────────────────────────────────────
총 = 4MB + 4KB
따라서 최악의 경우 4kb의 추가분(master page table)을 더해서 오히려 테이블이 하나일 때보다 메모리의 크기가 늘어난다.
5. Multi-level page table
64bit 시대가 오니까 2단계로는 master가 또 터진다. 그래서 단계를 더 늘린 게 multi-level. 발상은 똑같다
대가가 있다
단계가 늘면 변환 한 번에 메모리 접근이 늘어난다
- 원래 일반 테이블: 테이블 1번 + 데이터 1번 = 메모리 접근 2배
- Two-level: 테이블 2번 + 데이터 1번 = 3배
- 3-level이면 4배
6. 페이지 테이블을 페이징 하자
페이지 테이블도 메모리를 먹는데, 그 페이지 테이블마저 페이징할 수 없을까?
방법 1. 물리메모리에 페이지 테이블을 두기
- 주소 변환 없이 바로 접근 가능
- 페이지 테이블 주소를 알면 즉시 읽을 수 있다
- 단점: 페이지 테이블도 RAM을 계속 차지함
방법 2. 페이지 테이블도 가상 메모리에 넣자
프로세스 페이지를 디스크로 내보내듯이 페이지 테이블도 디스크로 내보내자
- 장점: 안쓰는 페이지 테이블을 디스크로 내려보내서 메모리 절약 가능
- 문제: CPU가 주소 변환을 위한 페이지 테이블(outer page table)도 디스크로 내려보낼 수 있다
- 해결법: outer page table(예: master page table)은 디스크로 내려보내지 않는다(wiring)
페이지 테이블도 페이징할 거면 운영체제 메모리도 페이징하자
커널 메모리 = 무조건 ram에 있어야 했지만 안쓰면 디스크로 내려보낼 수 있음
예외: interrupt handler(키보드 인터럽트, 타이머 인터럽트), exception handler(page fault) 이런건 내려보내면 안됨
7. TLB
TLB: 최근에 사용한 VPN → PFN 결과를 저장하는 초고속 캐시
TLB 히트나면 바로 데이터 읽기, 미스나면 Page table조회 후 데이터 읽기
MMU(Memory Management Unit): CPU 안에 있는 하드웨어
1. TLB is implemented in hardware
- TLB는 왜 빠른가?: Fully Associative Cache: TLB안의 엔트리들을 전부 동시에 검사
- TLB는 PTE전체를 저장한다
- PTE의 valid bit = 1이면 물리메모리에 있고 0이면 디스크에 있다.
- PTE 안의 PFN 정보와 원래 offset만 있으면 MMU가 물리 주소를 바로 만들 수 있다
- 프로세스가 백만 페이지를 가져도 실제로 지금 CPU가 쓰는건 몇페이지 뿐이다.
2. TLB exploit locality
- 프로세스가 백만 페이지를 가져도 실제로 지금 CPU가 쓰는건 몇페이지 뿐이다.
- TLB entry는 보통 16
48개 (× 4KB = 64192KB 커버), hotset, working set(지금 쓰는 페이지 묶음)을 담기 충분
- TLB entry는 보통 16
3. TLB는 fully associative인 이유
큰 L1/L2 캐시: entry가 수천 개 → 전부 fully associative로 만들면 comparator가 수천 개 필요 → 너무 비쌈 → direct/set associative 타협
TLB: entry가 16~48개뿐. 작으니까 전부 병렬 비교해도 comparator 비용 감당 가능. 게다가 TLB는 매 메모리 접근마다 쓰이고 conflict miss 한 번이 치명적이라 적중률이 생명
매핑방식 비교
| 방식 | 들어갈 자리 | 검색 범위 |
|---|---|---|
| Direct mapped | 딱 1곳 | 1칸만 봄 |
| Set associative | 한 set 안 아무 데나 | 그 set(몇 칸)만 봄 |
| Fully associative | 어디든 | 전체 병렬 검색 |
1-way 10.3% → 2-way 8.6% → 4-way 8.3% → 8-way 8.1%
1→2way가 제일 크게 떨어지고 그 뒤론 찔끔 (diminishing returns) → 그래서 큰 캐시는 2~4way에서 멈춤
"associativity 높이면 무조건 좋냐? → 체감이라 적당히
4. TLB miss가 나면 누가 페이지 테이블을 뒤져서 PTE에 TLB를 넣어주나?
1. Hardware managed TLB
- MMU가 페이지 테이블이 메모리 어디 있는지 안다 (CR3 같은 레지스터로)
- TLB miss 나면 MMU가 직접 페이지 테이블을 걸어가서(page walk) PTE를 찾아 TLB에 채움
- OS는 이 과정에 개입 안 함 — 하드웨어가 통째로 처리
- 대가: 페이지 테이블이 하드웨어가 정한 포맷이어야 함. MMU가 직접 읽어야 하니까 구조가 고정된다. OS 마음대로 못 바꿈.
2. Software managed TLB — OS가 처리
- TLB miss → OS로 trap(fault) 발생
- OS가 페이지 테이블에서 맞는 PTE를 찾아서 TLB에 적재
- 끝나면 exception에서 복귀, TLB가 이어서 진행
- 속도: 빨라야 함. 그래도 보통 20~200 cycle 듦 (fault 걸고 OS 핸들러 돌리는 비용)
- CPU의 ISA에 TLB 조작 명령어가 따로 있음 (OS가 TLB에 직접 써넣게)
- 장점: 페이지 테이블을 OS 편한 대로 아무 포맷이나 써도 됨. 하드웨어가 안 읽으니까. 유연함.
trade off
| 항목 | Hardware managed (x86) | Software managed |
|---|---|---|
| miss 처리 주체 | MMU(하드웨어) | OS(소프트웨어) |
| 속도 | 빠름 | 느림 (20~200 cycle, fault 비용) |
| 페이지 테이블 포맷 | 하드웨어 고정 | OS 자유 (유연) |
| OS 개입 | 없음 | trap으로 개입 |
5. TLB 관리
1. 일관성 유지 (consistency)
OS는 TLB와 페이지 테이블이 반드시 일치하도록 해야 한다.
2. Context switch 시 flush
대가: "싹 다 날려보내고 cold miss 시키고 반복". flush 직후 새 프로세스는 TLB가 텅 비어서 처음엔 전부 miss (cold start) 대안: TLB entry에 PID를 같이 저장 (ASID). 그러면 A랑 B의 entry가 PID로 구분되니까 flush 안 하고 공존 가능 → cold miss 안 생김
3. 교체 정책 (replacement policy)
TLB miss로 새 PTE가 들어와야 하면, 기존 PTE 하나를 쫓아내야(evict)한다.
- 누굴 쫓아낼지 고르는 게 TLB replacement policy
- victim(희생자) PTE를 고르는 일
- 하드웨어로 구현되고, 보통 단순 (예: LRU — 가장 오래 안 쓴 놈)
- 페이지 교체랑 달리 TLB 교체는 하드웨어가 빨리 해야 하니까 정교한 알고리즘 못 씀. 단순한 거 박아둠.
8. 지금까지 배운 TLB / 페이지 테이블 / 디스크를 메모리 한 번 읽을 때 실제로 어떻게 맞물려 돌아가는지
case1: 흔한 경우 (TLB hit, 99%+)
- CPU가 가상주소(VA)를 발생시켜 메모리에 접근하려 함
- VA가 MMU로 들어감. MMU가 VA를 [VPN | Offset]으로 쪼갬
- MMU가 VPN으로 TLB 조회 (fully associative라 전 엔트리 병렬 검색)
- TLB hit → 일치하는 엔트리에서 PFN을 꺼냄
- MMU가 PFN + Offset = 물리주소(PA) 조립
- MMU가 PA를 메모리(정확히는 캐시/메모리 버스)로 보냄 → 데이터가 CPU로 돌아옴
- 이 과정에서 OS의 개입은 없다
case2: TLB miss (1%): 두 가지 처리
- Hardware managed: MMU가 메모리의 페이지 테이블에서 PTE를 직접 로드. OS 개입 X (OS가 미리 테이블 깔아놔서 HW가 읽을 수 있음)
- Software managed: OS로 trap → OS가 테이블 lookup → PTE를 TLB에 적재 → exception 복귀 → TLB 계속 진행
case3: 재귀적 fault (recursive fault) -- 페이지 테이블 자체가 디스크로 paged out 됐으면?
테이블 lookup(HW든 OS든) 하려는데 테이블이 디스크에 있음 → 재귀적 page fault
page fault handler가 페이지 테이블을 물리 메모리로 끌어올림
그 다음 PTE를 TLB에 적재
TLB에 PTE 생기면 변환 재시작
흔한 경우: 그 PTE가 메모리에 있는 유효 페이지를 가리킴 (해결)
드문 경우: PTE에서 또 fault (예: 페이지가 invalid) → 한 단계 더
page fault의 종류
1. 권한 위반 (protection fault)
- read/write/execute 중 그 페이지에 허용 안 된 연산을 시도
- OS 처리: 보통 프로세스에게 fault 돌려보냄 (segfault), 또는 트릭을 부림
- copy-on-write, memory-mapped file 같은 거 (쓰기 시도를 가로채서 실제 복사/매핑)
2. Invalid (유효하지 않음) — 두 하위 경우
할당 안 됨 (not allocated): 그 가상 페이지가 아직 할당 안 된 영역 → OS가 프로세스에 fault 보내거나(잘못된 접근) 프레임 할당
메모리에 없음 (not in physical memory): 페이지가 디스크에 있음 → OS가 프레임 할당 → 디스크에서 읽어옴 → PTE를 그 프레임에 매핑 (이게 "page fault handling"의 핵심 동작)