- Published on
secondary storage
- Authors

- Name
- valery
- 1. Secondary Storage (여기서는 주로 HDD를 다룬다)
- 2. HDD의 구조
- 3. OS가 HDD를 어떻게 다루는지 (Managing Disks)
- 4. Disk Performance 3요소
- 5. Seek 병목을 줄이는 방법 (Disk Scheduling)
- 6. HDD 사용 실전 적용
1. Secondary Storage (여기서는 주로 HDD를 다룬다)
- 정의: 주기억장치(primary memory) 바깥의 저장장치. CPU가 직접 접근 못 함 → 명령어 직접 실행 불가, 데이터 직접 read/write 불가 (반드시 메모리로 올려야 씀)
- 특성 4가지
- 크다: 4TB 이상
- 싸다: 용량당 단가 낮음
- 영속적: 전원 끊겨도 데이터 유지 (비휘발성)
- 느리다: 접근에 ms 단위 (메모리 ns와 약 10^6 배 차이)
2. HDD의 구조
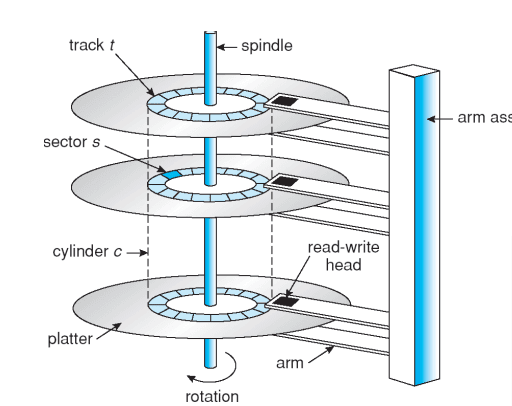
1. Mechanical (느림의 근원 = 물리적으로 움직이는 부품)
- 회전하는 platter(원판)
- arm assembly (head가 달린 팔)
2. Electronics
- disk controller: 요청 처리
- buffer: 캐시 메모리
- host interface: 호스트와 연결 (SATA 등)
3. 물리 단위
1. track: 한 platter 면의 동심원 하나
2. sector: track을 쪼갠 최소 read/write 단위
3. cylinder: 여러 면의 같은 반지름 track들을 수직으로 묶은 집합
(arm 한 위치에서 모든 head가 동시에 닿는 track들)
4. platter / surface / spindle
- platter: 원판 / surface: 원판의 한 면(위·아래) / spindle: platter들을 꽂아 회전시키는 축
3. OS가 HDD를 어떻게 다루는지 (Managing Disks)
- 전제: 디스크는 지저분한 물리장치(에러·bad block·missed seek) → OS의 일 = 이 난장판을 상위 SW로부터 숨기기
1. 접근 추상화 계층 (위=추상적, 아래=물리적)
- logical file (파일명, byte#) ← user library (user level)
- disk logical block (block#) ← filesystem (kernel level)
- physical disk block (surface/cylinder/sector) ← block layer (kernel level) 예: "a.txt" → block 1234 → S1, C3, S200. App은 "a.txt"만 알면 됨
2. 고수준 인터페이스 (예: SCSI)
- 옛날: OS가 cylinder/surface/track/sector 전부 지정 → OS가 디스크 파라미터를 다 알아야 했음
- 요즘: 디스크가 데이터를 논리 블록 배열 [0..N-1]로 노출 → OS는 블록 번호만 던지고, 디스크가 알아서 물리 위치로 매핑 → 물리 파라미터가 OS로부터 은폐됨 (sector 크기 제각각·remapping 등 복잡해진 현대 디스크 대응)
4. Disk Performance 3요소
1. Seek time
arm을 목표 cylinder로 이동. arm이 물리적으로 움직여야 함 — 제일 느림
2. Rotational latency
목표 sector가 head 밑에 올 때까지 회전 대기. rpm에 의존 — 느림
3. Transfer time
sector가 head 밑을 지나며 데이터 전송. 기록 밀도에 의존 — 빠름
→ 셋 중 Seek(arm 이동)이 압도적 병목
※ 만약 SSD라면? arm·회전이 없어 Seek·Rotation = 0 → 이 3요소와 아래 5번 스케줄링이 통째로 무의미해짐
분해해보니 Seek(arm 이동)이 압도적으로 느린 병목임을 발견
5. Seek 병목을 줄이는 방법 (Disk Scheduling)
1. 목적
- seek가 비싸다 → 요청 들어왔는데 디스크가 바쁘면 대기 요청을 disk queue에 쌓음
- 큐의 처리 순서를 재배치 → seek 줄이고 disk bandwidth↑
2. 알고리즘
(공통 예제: queue = 98,183,37,122,14,124,65,67 / head 시작 = 53)
1. FCFS: 도착순 그대로. 부하 낮으면 무난, 길어지면 왔다갔다 왕복 → 대기시간 김
2. SSTF: 현재 head에서 가장 가까운 요청 우선. seek 최소·요청률↑
단점: 가운데 블록 편애 → 가장자리 요청 starvation 가능
3. SCAN (엘리베이터): 한 방향 끝까지 처리 후 방향 반전. 대기시간 비균일
4. C-SCAN: 한 방향만 처리, 끝 찍으면 처음으로 점프해 다시 같은 방향
→ 대기시간 균일 (그 방향에 요청 없어도 끝까지 감)
5. LOOK / C-LOOK: SCAN/C-SCAN과 같되 디스크 끝(0·199)이 아니라 "그 방향의 마지막 요청"까지만 이동 → 헛걸음 제거
6. HDD 사용 실전 적용
1. 알고리즘 선택 기준
요즘은 스케줄링 안해주는게 제일좋다
- SSTF: 흔하고 직관적 → 무난한 기본값
- 부하 높은 시스템 → SCAN / C-SCAN 유리
- 기본 알고리즘으로는 SSTF 또는 LOOK이 합리적
- 성능은 요청 수·종류, 그리고 파일 할당 방식에 의존
2. I/O Scheduler가 해야 하는 일
- throughput↑: 요청 merge(개수 줄이기) + reorder·sort(seek 줄이기)
- starvation 방지: deadline 전에 요청 제출
- 프로세스 간 fairness 보장
- QoS(quality-of-service) 요구 보장
3. 요즘 disk (Modern Disks)
- intelligent controller: 작은 CPU + 수십 KB 메모리, 제조사 프로그램 탑재
- 기능: read-ahead(현재 track 선반입) / caching(자주 쓰는 블록) / command queuing / request reordering(seek·회전 최적화) / retry / bad block·track 식별·remapping
- → 디스크가 자체 스케줄링 수행. OS의 스케줄링을 무시·재정의 (자기 레이아웃을 OS보다 잘 아니까)