- Published on
schedule
- Authors

- Name
- valery
- 1. CPU scheduling의 목적
- 2. 스케줄링의 목적
- 3. 기본개념
- 4. state queue 흐름
- 5. scheduling 알고리즘 4가지
- 6. Priority Scheduling
- 7. Multilevel Queue Scheduling
- 8. MLFQ(Multilevel Feedback Queue)
- 9. UNIX 스케줄러
- 10. 멀티프로세서에서 스케줄랑
- 11. NUMA(Non-Uniform Memory Access)
1. CPU scheduling의 목적
- 실행가능한 프로세스 중 다음 프로세스를 뭘 CPU에 올릴건지 고르기
- 자주 발생하므로 빨라야한다.
2. 스케줄링의 목적
작업을 편식하지 않고, 쉬지않고 계속 작업하되 많이 해야하고 일정을 지켜야하며 빨리 처리해야한다.
1. starvation이 없어야한다.
- fairness: 모든 프로세스에게 동등하게 CPU에 접근할수있어야함
- Balance: CPU뿐만아니라 모든 장치들이 바쁘게 돌아야함.
starvation: 실행할 준비는 되어있는데 스케줄러가 기회를 안줘서 계속 못돌고 레디하고 있는 상태
- 안좋은 스케줄러, 동기화에서 기인한다.
2. batch system
- 작업을 한꺼번에 넣어두고 시스템이 순서대로 처리하는 방식
- throughput: 1시간에 최대한 많은 작업을 해야함
- Turn around time: 작업을 제출한 시간부터 완전히 끝날 때까지 걸리는 시간을 줄이기
- CPU utilaization: cpu에게 계속 일을 시켜야함.
3. Interactive system
- 사용자가 직접 입력하고 반응을 기다리는 시스템
- response time: 최대한 빨리 반응해야함
4. Real-time system
- 마감시간이 데드라인을 넘으면 안됨
- 작업 시간이 예측 가능해야함.
3. 기본개념
1. non-preemptive vs preemptive
- non-preemptive: yield호출해서 자발적으로 내려놓기
- 여기서는 우선순위가 더 높은게 나중에 들어와도 일단 이 프로세스 먼저 다 끝내고 다음 프로세스 받기
- preemptive: 인터럽트받아서 내려놓기
- 문제: 공유데이터 수정 중에 인터럽트 받으면?, 시스템 콜 중에 인터럽트 받으면?
- 동기화 문제가 따라온다(shared data, kernel state가 깨질 수 있다)
- 여기선 우선순위가 더 높은게 들어오면 바로 context switch
2. cpu-bound vs I/O-bound
cpu bound: 긴 cpu burst(CPU사용 시간을 길게 가져간다) I/O bound: 짧은 CPU burst + 잦은 I/O wait(잠깐 CPU사용하고 I/O로 빠진다) I/O가 반응성이 더 좋다
- 실제로 프로세스들이 CPU를 점유하는 시간은 짧다.
4. state queue 흐름
Running 상태에서
├─ time slice expired
│ └─ CPU를 너무 오래 써서 강제로 내려옴
│ → Ready Queue로 이동
│
├─ I/O request
│ └─ 디스크 읽기, 네트워크 요청 등
│ → I/O가 끝날 때까지 Waiting Queue로 이동
│ → I/O 완료 interrupt 발생
│ → Ready Queue로 복귀
│
├─ wait()
│ └─ child process 종료 같은 event를 기다림
│ → Waiting Queue로 이동
│ → child 종료
│ → Ready Queue로 복귀
│
└─ exit
└─ 실행 완료
→ Terminated
5. scheduling 알고리즘 4가지
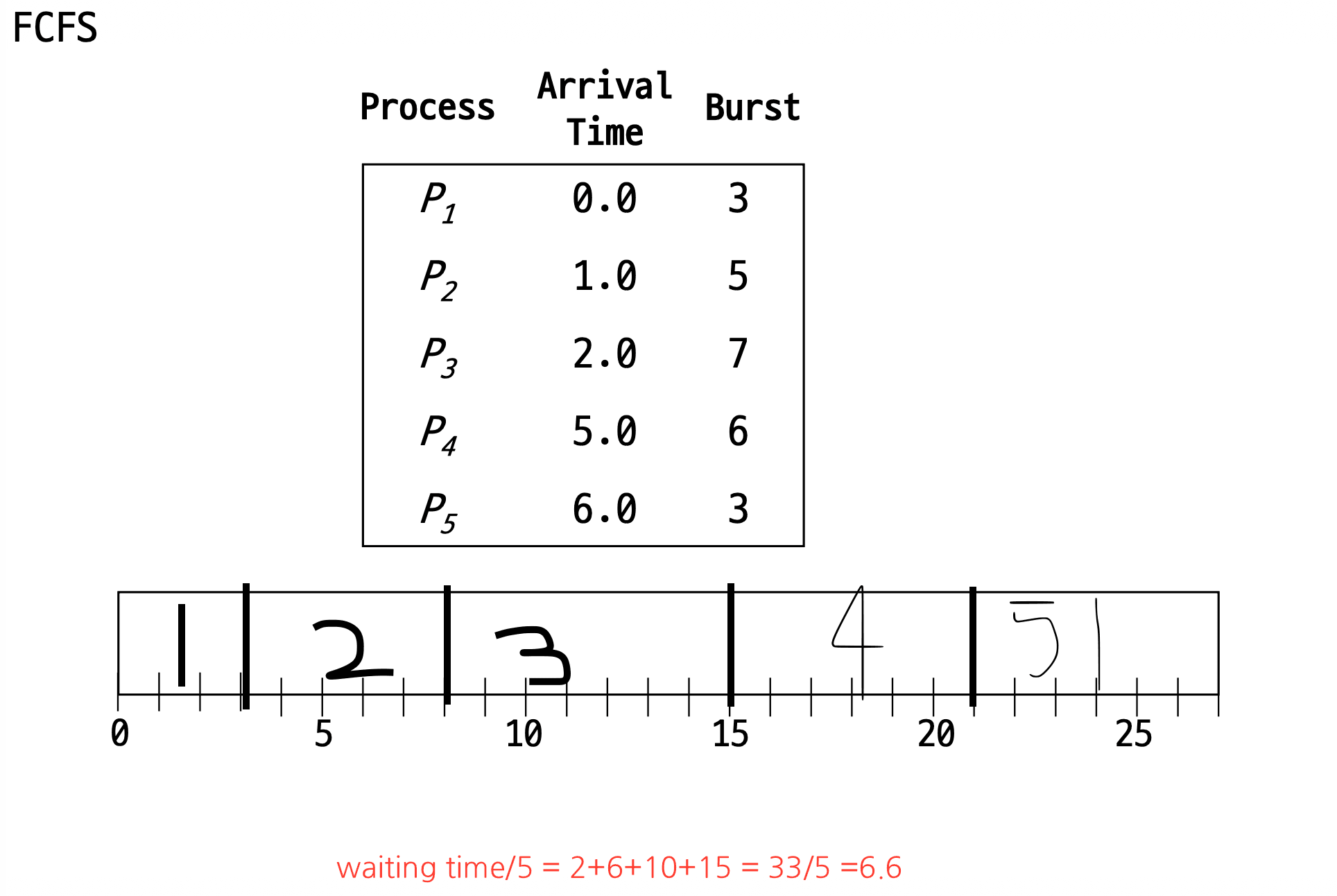
1. FCFS/FIFO
- ready queue에 도착한 순서대로 실행.
- 대체로 non-preemptive(P1실행 중에 P2가 도착해도 P1작업이 다 끝날 때 까지 기다린다)
- 장점: 구현이 단순
- 단점: waiting time이 길어질 수 있다(cpu burst가 긴 프로세스가 먼저 도착하면 아무리 짧은 프로세스가 나중에 도착해면 긴 프로세스를 먼저 실행하기 때문에), CPU가 중간에 길게 I/O사용하면 문제가 된다
2. SJF(Shortest Job First)
CPU burst가 가장 짧을 것으로 예상되는 프로세스를 먼저 실행
- 목적: 평균 waiting time 줄이기
- 조건: 모든 작업이 동시에 available(모든 프로세스가 이미 ready queue에 들어와있고 burst time도 알고 있을 때) 할 때
- 대체로 non-preemptive로 돌아감
- 문제점: 미래의 CPU burst time를 알 수 없다(그래서 과거 패턴보고 예측함), starvation이 발생 가능

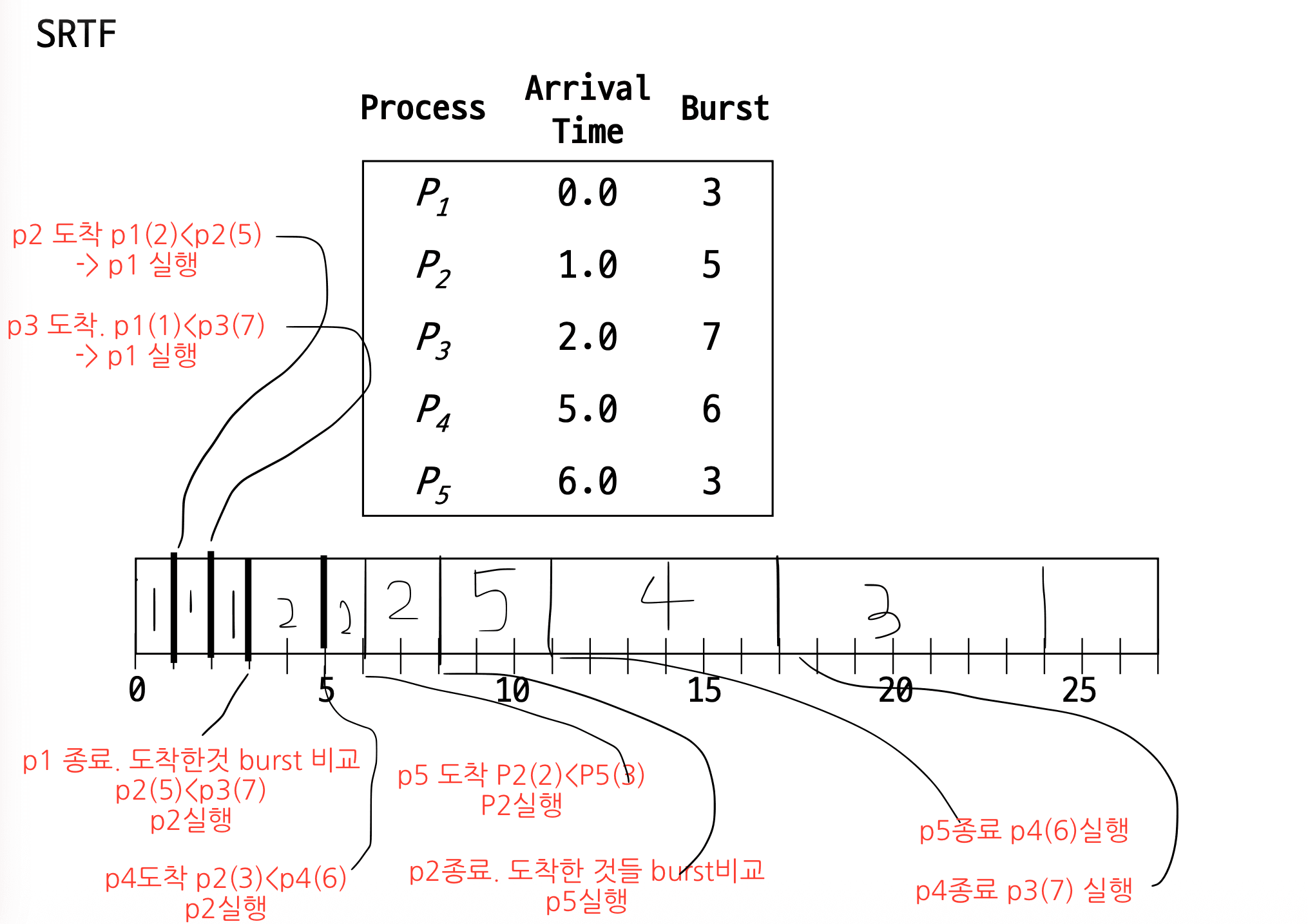
3. SRTF(Shortest Remaining Time First)
- SJF의 Preemptive방식
- 얘는 뭐가 다르냐, SJF에서 T1(arrival = 0, burst time = 5), T2(arrival = 2, burst time = 2)일 때
- T1은 T2가 도착해도 T1이 다 돈 다음에 T2로 넘어가지만
- SRTF는 T2가 도착했을 때 두개의 burst time를 비교해서(T1:3, T2:2) T2가 더 짧네? T2로 전환이 가능. 왜냐 preemptive이기 때문에.
4. RR(Round Robin)
time quantum만큼씩 돌아가면서 CPU를 나눠주는 방식 ready queue를 원형 큐로 FIFO를 개량한 버전.
- preemptive 방식

6. Priority Scheduling
ready queue에 있는 process 중 priority가 가장 높은 process를 선택해서 실행
- SJF, SRTF도 이것의 일종이다(burst가 짧은게 높은 priority)
- prority가 같다면 fifo나 RR적용도 가능하다
- non preemptive, preemptive 둘다 가능
- 우선순위는 다이나믹하게 바뀔 수 있다(ex: 오래기다린거 우선순위 높여주기, cpu 많이 쓴 프로세스 우선순위 낮추기)
- 이건 MLFQ(Multilevel Feedback Queue)로 이어진다.
Priority Scheduling의 문제점
1. Starvation
- 해결책: Aging: 오래된 프로세스 우선순위 높이기, cpu많이 먹는거 우선순위 낮추기
2. Priority inversion(우선순위 역전)
- 우선순위: P1 > P2 > P3
- P1과 P3는 같은 critical section에 들어가야함
- 근데 P3가 먼저 critical section에 들어가서 lock를 잡아버림
- 이떄 등장한 P2
- P2는 P3보다 우선순위가 높기에 P2부터 돌아감
- P3의 lock를 해제 못해서 계속 lock이 잡혀있어서 P1을 실행 못함
해결법
- PIP
- 낮은 priority 작업 priority 높여주기
- 위의 예시 같은 경우에 P3 우선순위 높여서 P3빨리 끝내게 하고 P1 다음에 돌리기
- PCP
- resource마다 priority ceiling 값을 미리 정해둠
- 어떤 thread가 그 resource를 lock하면
- 즉시 그 ceiling priority로 올라감
7. Multilevel Queue Scheduling
프로세스를 종류별 queue에 고정 배치하고, ueue마다 다른 알고리즘을 적용하는 방식
- 왜 분리하냐. 작업끼리 서로 원하는 목표가 다르기 때문에
foreground
- interective 작업
- response time 중요, 빨리 반응해야함
- ex: terminal, editor, gui, 사용자 입력처리
- 알고리즘 RR 사용
background
- batch 작업
- throughput, turnaround time 중요, 많이 처리하고 끝내는게 중요
- ex: 대량 계산, 로그처리, 오래걸리는 작업
- 알고리즘: FCFS사용
queue간의 스케줄링
Fixed priority scheduling: foreground를 먼저 다 처리하고, 그 다음 background를 처리
- 문제점: starvation
여러 queue를 priority 순서로 쌓아두고, 위 queue부터 CPU를 주는 구조”를 보여주는 그림
따라서 아예 큐를 분리해놓으면 누가 우선순위가 높은지 파악하는 오버헤드가 적다
8. MLFQ(Multilevel Feedback Queue)
멀티레벨큐에 aging기법을 큐 차원에서 적용한거
multilevel queue와의 차이점
Multilevel Queue: 프로세스가 한 queue에 고정됨
Multilevel Feedback Queue: 프로세스가 실행 패턴에 따라 queue 사이를 이동함
흐름
→ 일단 높은 priority에서 실행
→ CPU를 오래 쓰면 아래로 내림
→ 짧게 쓰고 I/O 하면 위에 둠
그리고 오래 실행안한 큐 우선순위높임
aging기법
9. UNIX 스케줄러
preemptive + priority-based + round-robin + dynamic priority + MLFQ
- Preemptive: 더 높은 priority process가 오면 현재 process를 끊을 수 있음
- Priority-based: priority 높은 process 먼저 실행
- Round-robin: 같은 priority 안에서는 time slice로 번갈아 실행
- Dynamic priority
- CPU를 많이 쓰면 priority 감소
- I/O-bound 또는 interactive process는 priority 우대
- MLFQ와 유사: process 행동에 따라 priority가 바뀜
- Aging: 오래 기다린 process의 starvation 방지
10. 멀티프로세서에서 스케줄랑
지금까지는 cpu가 1개일 때만 다뤘는데 cpu가 여러개이면 어떻게 스케줄링해야하지?
P1, P2, P3, P4
CPU0, CPU1, CPU2, CPU3
→ P1은 CPU0?
→ P2는 CPU1?
→ 아니면 CPU마다 queue를 따로 둘까?
→ 특정 CPU에 일이 몰리면 어떻게 하지?
- load balance: CPU들 사이에 작업량을 적절히 나눠서, 어떤 CPU는 놀고 어떤 CPU는 바쁘지 않게 하는 것
- process affinity: 가능하면 같은 프로세스는 같은 cpu에서 돌려야한다. 캐시 때문에
11. NUMA(Non-Uniform Memory Access)
메모리 접근 시간이 균일하지 않음
- 물리적인 메모리 위치가 어디냐? 이거까지 고려해서 설계해야함
- Multithreaded multicore는 core 하나를 더 효율적으로 쓰려고 hardware thread를 여러 개 두는 구조이고, 스케줄러는 logical CPU가 진짜 독립 CPU가 아니라는 점을 고려해야 한다.