- Published on
memory
- Authors

- Name
- valery
- 1. 메모리 관리의 목표
- 2. Single / Batch Programming
- 3. Multiprogramming
- 4. 여러 프로세스를 메모리에 올리는 방법(구식)
- 5. Virtual Memory
1. 메모리 관리의 목표
- 프로그래밍 하기 편한 추상화 제공(배열같은거)
- 부족한 메모리 자원을 여러 프로세스에 분배
- 최소한의 오버헤드로 성능 극대화
- 프로세스간 격리 제공
- 이게 그래서 왜 어려움?
2. Single / Batch Programming
- 프로세스 하나만 메모리에 올려서 실행하던 시절
- 프로그램이 실제 RAM 주소(physical address)를 직접 사용
- 한 번에 user program 하나만 메모리에 올라간다
3. Multiprogramming
여러 프로세스를 동시에 메모리에 올리는 상황에서 프로세스끼리 서로의 메모리 영역을 침범하면 안되서 자신 영역만 사용하는 Protection이 필요하다. 또한 프로세스는 주소를 계속 사용해서 주소변환이 느려지면 프로세스 전체가 느려진다. 따라서 빠르게 virtual > physical로 바꿔주는 (fast translation)이 필요하다. 또한 context switch 때 memory설정도 빠르게 바꿔줘야한다(fast context switch).
virtual address vs physical address
프로세스가 보는 메모리 주소와 실제 메모리 주소는 다를 수 있다. 이는 커널이 관리한다
4. 여러 프로세스를 메모리에 올리는 방법(구식)
1. Fixed Partitions
- 물리 메모리를 고정된 크기의 partition들로 나눈다
- 각 파티션에는 하나의 프로세스가 들어간다
- 필요한 하드웨어는 base register이다
- Physical address = virtual address + base register
- context switch가 일어나면 OS가 현제 프로세스에 맞는 base register값을 로드한다
장점
- 구현이 쉽다
- contextswitch가 빠르다
단점
- Internal fragmentation(내부 단편화): 파티션 안에 메모리 영역이 남아있어도 다른 프로세스에서 사용하지 못한다
- 파티션 사이즈가 모든 프로세스에 맞지 않다(1번이랑 비슷한 얘기)
그래서 나온 개선 버전
- 물리 메모리를 여러가지 크기로 자른 파티션들을 준비한다
- 어떤 프로세스가 메모리 얼마나 쓰는지를 아니까 이걸 보고 메모리 영역 스캔한 다음에 알맞은 사이즈 파티션에 집어넣는다
- 스캔과정이 있어서 오버헤드가 더 크다
2. Variable Partitions
process 크기에 맞춰 partition 크기를 다르게 잡는 방식
- 물리 메모리를 variable-sized partition으로 나눈다.
- 필요한 하드웨어는 base register와 limit register이다.
- base register는 process가 physical memory에서 시작하는 주소를 저장한다.
- limit register는 process가 접근 가능한 범위를 저장하며 protection 역할을 한다.
- Physical address = virtual address + base register
- virtual address가 limit 범위를 넘으면 protection fault가 발생한다.
- 레지스터 값 하나만 바꿔도 되서 오버헤드가 적다(근데 오버헤드가 적어도 fixed보단 많음)
Allocation strategies
- First fit
- 들어갈 수 있는 첫 번째 hole에 배치한다.
- Best fit
- 들어갈 수 있는 hole 중 가장 작은 hole에 배치한다.
- Worst fit
- 가장 큰 hole에 배치한다.
Advantages
- Internal fragmentation이 없다: process 크기에 딱 맞게 partition을 할당하기 때문이다.
Problems
- External fragmentation이 발생한다: job을 load하고 unload하는 과정에서 physical memory 곳곳에 작은 빈 공간들이 흩어지기 때문에
Solutions to external fragmentation
- Compaction: 흩어진 process들을 한쪽으로 몰아서 hole을 크게 합침
- Paging: 메모리를 고정 크기 page/frame으로 나눠서 연속 공간 요구를 없앰
- Segmentation: 프로그램을 의미 단위 segment로 나눠 관리함
3. Overlays
- 프로그램 전체를 한 번에 메모리에 올리지 않는다.
- 실행 시점에 필요한 instruction과 data만 메모리에 올린다.
- 동시에 필요하지 않은 부분들은 같은 메모리 영역을 번갈아 사용한다.
장점
- 프로세스가 필요한 메모리가 메모리 영역보다 클 때 사용 가능
- 특별한 OS적인 지원이 필요 없다
단점
- 구현이 어려움
예시: two-pass assembler
- Symbol table, common routines, overlay driver는 항상 필요하다.
- Pass 1과 Pass 2는 동시에 필요하지 않다.
- 따라서 Pass 1과 Pass 2를 같은 메모리 영역에 번갈아 올릴 수 있다.
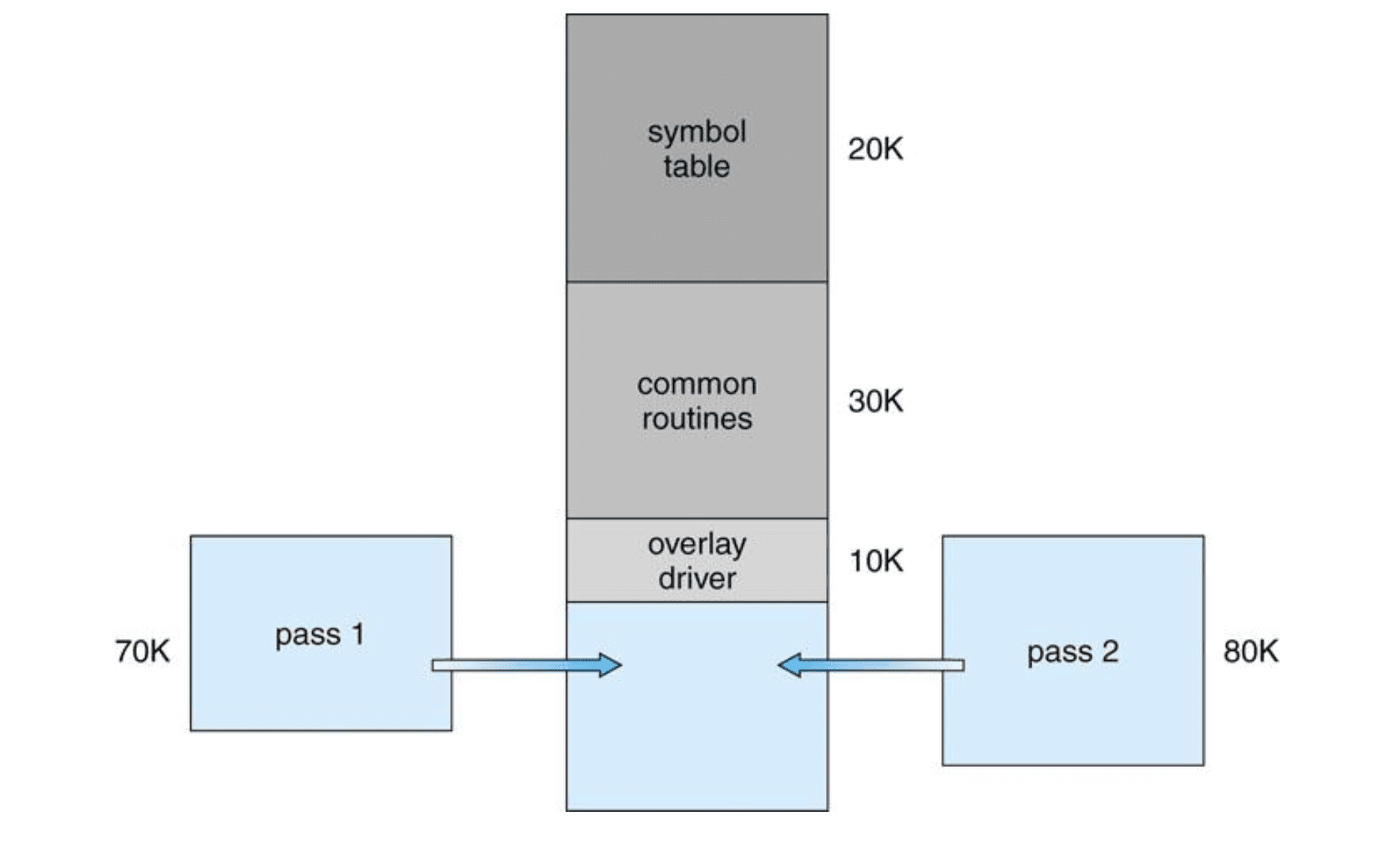
전체 크기:
20K + 30K +10K + 70K + 80K = 210K
Overlay 사용 시 필요한 크기:
20K + 30K + 10K + max(70K, 80K) = 140K
4. Swapping
- 메모리에 올라와 있던 process를 잠시 backing store(disk)로 내보낸다.
- 나중에 다시 메모리로 가져와 실행을 계속한다.
흐름
- process가 main memory에 있다.
- 메모리가 부족하거나 다른 process를 실행해야 하면, OS가 process를 backing store로 swap out한다.
- 나중에 그 process를 다시 실행할 때 backing store에서 main memory로 swap in한다.
Backing store
- 빠른 disk이다.
- 모든 memory image의 복사본을 담을 만큼 충분히 커야 한다.
- 각 memory image에 직접 접근할 수 있어야 한다.
Problems
- swap time의 대부분은 transfer time이다.
- transfer time은 swap하는 memory 양에 직접 비례한다.
- 처리중인 I/O가 있는 process는 swap하면 문제가 생길 수 있다.
5. Virtual Memory
1. 핵심 개념
Virtual memory는 process가 실제 physical memory 주소를 직접 사용하지 않고, virtual address를 사용하게 하는 방식이다.
- process는 자기만의 독립적인 virtual address space를 가진다.
- 같은 virtual address라도 process마다 다른 physical address에 mapping될 수 있다.
- CPU와 OS가 virtual address를 physical address로 변환한다.
- 이 변환에는 page table 같은 자료구조가 사용된다.
2. 왜 필요한가?
여러 process를 동시에 실행할 때, process마다 독립적인 메모리 공간을 가진 것처럼 보이게 하기 위해 필요하다.
- process끼리 서로의 메모리를 직접 침범하지 못하게 한다.
- programmer가 실제 RAM 위치를 신경 쓰지 않아도 된다.
- process는 크고 연속된 메모리를 가진 것처럼 사용할 수 있다.
- 실제 physical memory에는 필요한 부분만 올라와 있어도 된다.
3. 주소 변환 흐름
- CPU instruction이 virtual address를 만든다.
- hardware가 OS의 도움을 받아 주소를 변환한다.
- page table을 이용해 virtual address에 대응되는 physical address를 찾는다.
- 실제 physical memory에 접근한다.
Process
→ Virtual address
→ OS & CPU with Page Table
→ Physical address
4. Virtual Address Space
Virtual address space는 process가 사용할 수 있는 virtual address 전체 범위이다.
일반적인 구조는 다음과 같다.
높은 주소
├─ kernel virtual memory
├─ user stack
├─ unused area
├─ run-time heap
├─ read/write segment (.data, .bss)
└─ read-only segment (.text, .rodata)
낮은 주소
- stack은 runtime에 생성된다.
- heap은 malloc 같은 동적 메모리 할당으로 관리된다.
.data,.bss는 읽기/쓰기 가능한 전역 데이터 영역이다..text,.rodata는 코드와 읽기 전용 데이터 영역이다.
5. Lazy Loading
Virtual memory에서는 프로그램 전체를 처음부터 physical memory에 올릴 필요가 없다.
- 필요한 부분만 physical memory에 올린다.
- 아직 필요하지 않은 부분은 disk에 있어도 된다.
- process는 전체 address space가 memory에 있는 것처럼 실행된다. 이 방식이 demand paging으로 이어진다.
6. 장점
- logical memory와 physical memory를 분리한다.
- process마다 독립적인 address space를 제공한다.
- protection에 유리하다.
- physical memory보다 큰 process도 실행할 수 있다.
- 실제로 사용하는 부분만 memory에 올릴 수 있어 더 많은 program을 동시에 실행할 수 있다.
- demand paging을 사용하면 필요한 page만 가져오므로 I/O가 줄어들 수 있다.
- file과 address space 공유가 쉬워진다.
- process creation에 효율적이다.
7. 단점
Virtual memory는 performance overhead가 있다.
구체적으로는 다음 비용이 생긴다.
- virtual address를 physical address로 변환하는 시간 비용
- page table을 저장하고 관리하는 공간 비용
- 필요한 page가 memory에 없을 때 발생하는 page fault 비용
8. 구현 방식
Virtual memory는 대표적으로 다음 방식으로 구현된다.
- Paging
- Segmentation